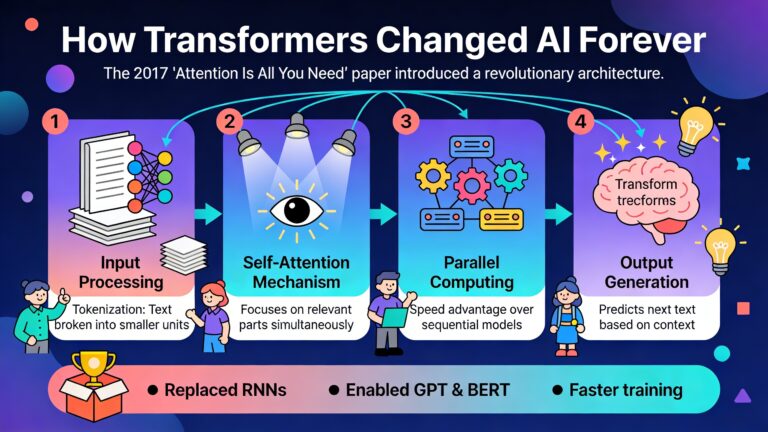
Inleiding tot het TongYi Fun-Audio-Chat model
In de snel evoluerende wereld van kunstmatige intelligentie zien we steeds meer doorbraken op het gebied van spraaktechnologie. Een van de meest opvallende ontwikkelingen is het TongYi Fun-Audio-Chat speech to speech model, een geavanceerd systeem dat de manier waarop we met AI communiceren fundamenteel verandert. Dit model, ontwikkeld door Alibaba Cloud, vertegenwoordigt een nieuwe generatie van spraakinteractie waarbij natuurlijke conversaties met minimale vertraging centraal staan.
Het Fun-Audio-Chat model is geen gewone spraakassistent. Het gaat veel verder dan simpelweg commando’s uitvoeren of vragen beantwoorden. Dit systeem begrijpt emoties, reageert met empathie en kan zelfs complexe taken uitvoeren door middel van spraakgestuurde functie-aanroepen. In deze blogpost duiken we diep in wat dit model precies is, hoe het werkt, wie erachter zit en waar het echt uitblinkt.
Wat is het TongYi Fun-Audio-Chat model?
Het TongYi Fun-Audio-Chat model is een Large Audio Language Model dat speciaal is ontworpen voor natuurlijke, laag-latente spraakinteracties. In tegenstelling tot traditionele spraaksystemen die eerst spraak naar tekst converteren, vervolgens de tekst verwerken en dan weer tekst naar spraak omzetten, werkt dit model direct met audio-input en audio-output.
Het systeem maakt deel uit van de bredere Qwen-familie van AI-modellen van Alibaba Cloud en is specifiek geoptimaliseerd voor spraakgebaseerde toepassingen. Het model kan verschillende taken uitvoeren:
- Gesproken vraag-en-antwoord: Het systeem kan complexe vragen begrijpen en beantwoorden in natuurlijke spraak
- Audio-begrip: Het herkent niet alleen woorden, maar ook toon, emotie en context
- Spraakgestuurde functie-aanroepen: Gebruikers kunnen via natuurlijke spraakcommando’s complexe taken laten uitvoeren
- Spraak-instructie-opvolging: Het model kan gedetailleerde instructies begrijpen en uitvoeren
- Stem-empathie: Het systeem detecteert emotionele nuances en reageert daar gepast op
De technische architectuur
Wat het Fun-Audio-Chat model echt onderscheidt is de innovatieve Dual-Resolution Speech Representations architectuur. Deze technologie combineert een efficiënte 5Hz gedeelde backbone met een verfijnde 25Hz head. Dit klinkt misschien technisch, maar het betekent in de praktijk dat het systeem rekenkracht bespaart terwijl het toch hoge spraakkwaliteit behoudt.
Daarnaast maakt het model gebruik van Core-Cocktail training, een trainingsmethode die ervoor zorgt dat de sterke tekstverwerking van het onderliggende taalmodel behouden blijft. Dit is cruciaal omdat veel spraakmodellen hun tekstbegrip verliezen wanneer ze worden getraind op spraakdata.
Wie zit er achter het TongYi Fun-Audio-Chat model?
Het Fun-Audio-Chat model is ontwikkeld door het TongYi Fun Team binnen Alibaba Group, een van de grootste technologiebedrijven ter wereld. Alibaba Cloud, de cloudcomputing-divisie van Alibaba, staat bekend om zijn geavanceerde AI-onderzoek en -ontwikkeling.
De Qwen-familie
Het Fun-Audio-Chat model maakt deel uit van de Qwen-modellenreeks (ook wel Tongyi Qianwen genoemd), die verschillende gespecialiseerde AI-modellen omvat. Deze familie bevat onder andere:
- Qwen-Max, Qwen-Plus en Qwen-Flash: Algemene taalmodellen voor verschillende complexiteitsniveaus
- Qwen-VL: Visuele begripsmodellen die afbeeldingen kunnen analyseren
- Qwen-Omni: Multimodale modellen die tekst, afbeeldingen, audio en video kunnen verwerken
- Qwen-Coder: Gespecialiseerde modellen voor programmeren en code-generatie
Het Fun-Audio-Chat model bouwt voort op deze expertise en combineert de kracht van taalverwerking met geavanceerde spraaktechnologie.
Samenwerking met partners
Een interessant voorbeeld van hoe Alibaba Cloud deze technologie toepast is de samenwerking met Teenii.AI voor de ontwikkeling van de Mooni M1, een AI-gezelschapsrobot voor kinderen. Dit apparaat, dat werd gelanceerd tijdens de “Miao Wu · Intelligent Fun Tongyi AI Hardware Exhibition” in Shenzhen, laat zien hoe het Fun-Audio-Chat model in praktische toepassingen wordt geïntegreerd.
De Mooni M1 is geen traditionele spraakassistent, maar een emotionele metgezel die de unieke taallogica van kinderen begrijpt, emotionele schommelingen herkent en met empathie reageert. Dit demonstreert de veelzijdigheid van het onderliggende Fun-Audio-Chat model.
Hoe werkt het Fun-Audio-Chat model?
Het Fun-Audio-Chat model werkt fundamenteel anders dan traditionele spraaksystemen. Laten we de werking stap voor stap bekijken.
Directe audio-verwerking
In plaats van de traditionele pipeline (spraak → tekst → verwerking → tekst → spraak) verwerkt het Fun-Audio-Chat model audio direct. Dit heeft verschillende voordelen:
- Lagere latentie: Doordat er geen tussenstappen nodig zijn, reageert het systeem sneller
- Behoud van paralinguïstische informatie: Toon, emotie en andere niet-verbale signalen blijven behouden
- Natuurlijkere interacties: Het systeem kan overlappen in spraak aan, vergelijkbaar met menselijke gesprekken
Empathische spraakherkenning
Een van de meest indrukwekkende aspecten van het Fun-Audio-Chat model is het vermogen om emoties te herkennen en daar gepast op te reageren. Het systeem kan twee soorten empathie tonen:
Semantische empathie: Het begrijpt de emotionele context van wat er gezegd wordt op basis van de inhoud. Als iemand bijvoorbeeld vertelt over een moeilijke dag, herkent het systeem dit en reageert met begrip.
Paralinguïstische empathie: Het detecteert emoties door middel van toon, tempo en prosodie (de melodie van spraak). Zelfs zonder expliciete emotionele markers kan het systeem spanning, vreugde of verdriet herkennen in iemands stem.
Spraak-instructie-opvolging
Het Fun-Audio-Chat model ondersteunt geavanceerde spraak-instructie-opvolging. Dit betekent dat gebruikers via natuurlijke spraakcommando’s kunnen bepalen hoe het systeem moet reageren. Je kunt bijvoorbeeld vragen om:
- Een bepaalde emotie in de stem (bijvoorbeeld enthousiast of kalm)
- Een specifieke spreekstijl (formeel of informeel)
- Aanpassingen in snelheid, toonhoogte of volume
Het model begrijpt deze instructies en voert ze in real-time uit tijdens het gesprek, wat zorgt voor een zeer gepersonaliseerde ervaring.
Spraakgestuurde functie-aanroepen
Een krachtige functie van het Fun-Audio-Chat model is de mogelijkheid om complexe taken uit te voeren via natuurlijke spraakcommando’s. Het systeem kan:
- Spraak-instructies begrijpen en de benodigde functies identificeren
- Zowel enkele als parallelle functie-aanroepen ondersteunen
- Taken uitvoeren zonder dat gebruikers technische commando’s hoeven te kennen
Dit maakt het model bijzonder geschikt voor toepassingen waarbij gebruikers hands-free moeten werken of waarbij complexe workflows via spraak moeten worden aangestuurd.
Waar is het Fun-Audio-Chat model sterk in?
Het TongYi Fun-Audio-Chat model behaalt state-of-the-art prestaties op verschillende benchmarks. Laten we de belangrijkste sterke punten in detail bekijken.
Gesproken vraag-en-antwoord
Het model presteert uitstekend bij het beantwoorden van gesproken vragen, zowel eenvoudige conversationele vragen als complexe redeneervragen. Het kan:
- Gesproken vragen begrijpen, zelfs met dialecten of accenten
- Nauwkeurige en gedetailleerde antwoorden geven in natuurlijke spraak
- Context behouden over meerdere beurten in een gesprek
Audio-begrip
Het Fun-Audio-Chat model demonstreert sterke audio-begripsvaardigheden over diverse audio-modaliteiten:
- Spraaktranscriptie: Nauwkeurige omzetting van spraak naar tekst
- Inhoudsanalyse: Begrip van de betekenis en context van gesproken inhoud
- Geluidsbronidentificatie: Herkenning van verschillende geluiden en hun bronnen
- Achtergrondgeluidsherkenning: Detectie van omgevingsgeluiden en hun betekenis
- Muziekanalyse: Begrip van muzikale elementen en stijlen
Full-duplex interactie
Een bijzonder indrukwekkende functie is de Fun-Audio-Chat-Duplex variant, die full-duplex spraakinteractie ondersteunt. Dit betekent dat het systeem:
- Gelijktijdige tweerichtingscommunicatie mogelijk maakt
- Kan luisteren terwijl het spreekt
- Natuurlijk omgaat met onderbrekingen door de gebruiker
- Naadloze turn-taking ondersteunt, vergelijkbaar met menselijke gesprekken
Deze functie creëert veel natuurlijkere en efficiëntere mens-machine spraakinteracties die menselijke gesprekken nauwkeurig nabootsen.
Meertalige ondersteuning
Hoewel het model oorspronkelijk is ontwikkeld met focus op Chinees en Engels, ondersteunt de bredere Qwen-familie meer dan 100 talen en dialecten. Dit maakt het systeem geschikt voor internationale toepassingen en diverse gebruikersgroepen.
Veiligheid en contentfiltering
Een cruciaal aspect, vooral bij toepassingen voor kinderen zoals de Mooni M1, is de ingebouwde veiligheid. Het Fun-Audio-Chat model heeft:
- Strikte contentfiltering ingebouwd in de onderliggende architectuur
- Waardeafstemming om ervoor te zorgen dat alle interacties voldoen aan beschermingsnormen
- Mechanismen om ongepaste informatie te voorkomen
Praktische toepassingen en use cases
Het Fun-Audio-Chat model is geschikt voor een breed scala aan toepassingen:
Klantenservice en ondersteuning
Het model kan worden ingezet voor intelligente spraakgestuurde klantenservice die niet alleen vragen beantwoordt, maar ook emoties herkent en daar gepast op reageert. Dit leidt tot meer tevreden klanten en efficiëntere ondersteuning.
Educatieve toepassingen
Zoals gedemonstreerd met de Mooni M1, is het model uitstekend geschikt voor educatieve doeleinden. Het kan kinderen helpen bij taalontwikkeling, emotionele expressie en sociale groei door natuurlijke, empathische interacties.
Toegankelijkheid
Voor mensen met visuele beperkingen of andere handicaps biedt het model een natuurlijke manier om met technologie te interageren zonder afhankelijk te zijn van schermen of toetsenborden.
Hands-free bediening
In situaties waar mensen hun handen nodig hebben (bijvoorbeeld tijdens het koken, autorijden of werken), biedt het model een veilige en efficiënte manier om taken uit te voeren via spraak.
Beperkingen en toekomstige ontwikkelingen
Hoewel het Fun-Audio-Chat model indrukwekkende mogelijkheden heeft, is het belangrijk om ook de beperkingen te erkennen. De full-duplex variant is nog in ontwikkeling en kan in sommige gevallen hallucinaties vertonen of antwoorden genereren die niet volledig accuraat zijn.
Alibaba Cloud werkt continu aan verbeteringen om de betrouwbaarheid van het model te verhogen en hallucinatieproblemen te verminderen. Gebruikers moeten zich bewust zijn dat de antwoorden van het model fouten of inconsistenties kunnen bevatten, vooral in complexe of dubbelzinnige scenario’s.
De toekomst van spraakinteractie
Het TongYi Fun-Audio-Chat speech to speech model vertegenwoordigt een belangrijke stap voorwaarts in de evolutie van spraaktechnologie. Door directe audio-verwerking, empathische reacties en geavanceerde functionaliteiten zoals full-duplex interactie te combineren, zet het model een nieuwe standaard voor natuurlijke mens-machine communicatie.
De lancering van producten zoals de Mooni M1 laat zien dat deze technologie niet alleen theoretisch interessant is, maar ook praktische waarde heeft in het dagelijks leven. Naarmate de technologie verder evolueert en verbetert, kunnen we verwachten dat spraakinteractie met AI steeds natuurlijker en nuttiger wordt, waardoor de kloof tussen mens en machine verder wordt verkleind.