De fascinerende reis van een taalmodel
Large Language Models (LLM’s) zijn vandaag overal. Ze helpen ons met teksten schrijven, vragen beantwoorden en zelfs code genereren. Maar hoe werken deze gigantische neurale netwerken eigenlijk? En belangrijker nog, hoe evolueren ze van een leeg canvas naar een intelligent systeem dat menselijke taal begrijpt? In deze blogpost duiken we in de theoretische werking van LLM’s en bekijken we de verschillende fases van hun ontwikkeling.
Wat zijn LLM’s eigenlijk?
Voor we in de technische details duiken, is het belangrijk om te begrijpen wat LLM’s precies zijn. Een Large Language Model is een gigantisch neuraal netwerk dat getraind wordt op enorme hoeveelheden tekstdata. Het doel? Een universele representatie leren van taal en patronen daarin herkennen. Modellen zoals ChatGPT, Claude of Gemini.
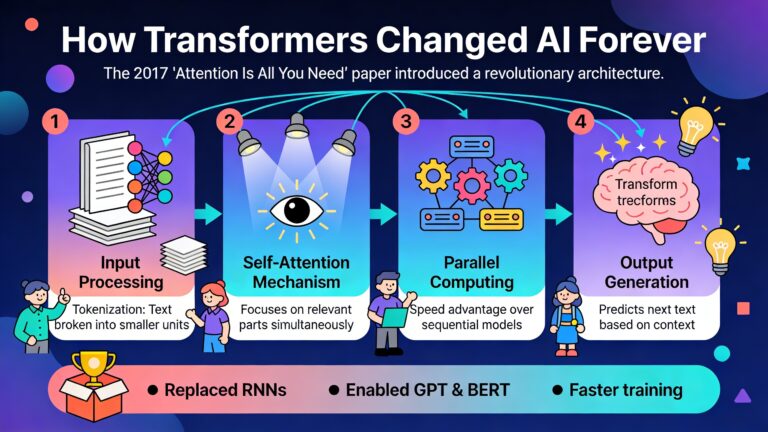
Deze modellen zijn gebaseerd op de transformer-architectuur, een doorbraak uit 2017 die de manier waarop we met taal werken volledig heeft veranderd. Maar de weg van een leeg model naar een bruikbaar systeem is lang en complex, met verschillende cruciale fases.
Fase 1: data voorbereiding
Alles begint met data. En niet zomaar een beetje data, maar gigantische hoeveelheden tekst uit allerlei bronnen: websites, boeken, wetenschappelijke artikelen, code en nog veel meer. Deze fase is crucialer dan je zou denken, want de kwaliteit en diversiteit van de data bepalen grotendeels wat het model later kan.
De kunst van het mixen
Een interessant theoretisch vraagstuk in deze fase is hoe je verschillende databronnen moet combineren. Moet je evenveel wetenschappelijke teksten als sociale media posts gebruiken? Hoe balanceer je verschillende talen? Onderzoekers hebben ontdekt dat de juiste mix van data cruciaal is voor goede prestaties. Te veel van één type data kan leiden tot een model dat te gespecialiseerd is.
Een ander belangrijk aspect is deduplicatie. Als dezelfde tekst meerdere keren in de trainingsdata voorkomt, gaat het model deze letterlijk onthouden in plaats van te generaliseren. Dit kan leiden tot privacyproblemen en verminderde prestaties op nieuwe taken. Daarom worden geavanceerde technieken gebruikt om duplicaten te verwijderen zonder waardevolle informatie te verliezen.
Het memorisatieprobleem
Een fascinerend theoretisch probleem is memorisatie. LLM’s kunnen letterlijk stukken tekst uit hun trainingsdata reproduceren. Dit is niet altijd gewenst, vooral niet als het gaat om gevoelige informatie. Onderzoekers proberen te begrijpen wanneer en waarom modellen memoriseren versus generaliseren. Het blijkt dat simpelere, vaker voorkomende patronen makkelijker onthouden worden.
Fase 2: model voorbereiding
Eens de data klaar is, moet je beslissen welke architectuur je gaat gebruiken. Dit is geen triviale keuze. De architectuur bepaalt wat het model theoretisch kan leren en hoe efficiënt het werkt.
Transformers en hun alternatieven
De meeste moderne LLM’s gebruiken de transformer-architectuur. Deze architectuur heeft een belangrijk voordeel: het attention-mechanisme laat het model focussen op relevante delen van de input. Maar transformers hebben ook een nadeel: ze worden kwadratisch trager naarmate de input langer wordt.
Daarom onderzoeken onderzoekers alternatieven zoals lineaire modellen en recurrent neural networks (RNNs). Deze zijn efficiënter maar hebben vaak minder expressieve kracht. Het is een klassiek no free lunch probleem: je kan niet tegelijk maximale prestaties en maximale efficiëntie hebben.
De expressiviteit van architecturen
Een belangrijk theoretisch vraagstuk is: wat kan een bepaalde architectuur in principe leren? Onderzoekers hebben aangetoond dat transformers Turing-compleet zijn onder bepaalde aannames. Dit betekent dat ze in theorie elk algoritme kunnen uitvoeren. In de praktijk zijn er natuurlijk beperkingen door eindige precisie en grootte.
Fase 3: training
Nu komt het echte werk: het model trainen op de voorbereide data. Deze fase is computationeel het meest intensief en kost vaak miljoenen euro’s aan rekenkracht.
Scaling laws: groter is beter?
Een van de meest fascinerende ontdekkingen van de laatste jaren zijn de scaling laws. Deze wiskundige relaties beschrijven hoe de prestaties van een model verbeteren naarmate je meer data, parameters of rekenkracht gebruikt. Het blijkt dat deze relaties verrassend voorspelbaar zijn volgens machtswetten.
Maar er is een addertje onder het gras. Deze wetten gelden alleen onder bepaalde voorwaarden. Als je bijvoorbeeld synthetische data gebruikt die door AI gegenereerd is, kunnen de scaling laws breken. Dit leidt tot het fenomeen van “model collapse”, waarbij het model steeds slechter wordt.
Waar komt intelligentie vandaan?
Een diepgaande theoretische vraag is: hoe ontstaat intelligentie uit simpele next-token predictie? Het antwoord lijkt te liggen in compressie. Door data efficiënt te comprimeren, moet het model de onderliggende patronen en structuren leren. Hoe beter de compressie, hoe beter het begrip van de data.
Fase 4: alignment
Een getraind model kan veel, maar het doet niet automatisch wat we willen. De alignment-fase zorgt ervoor dat het model zich gedraagt volgens menselijke waarden en intenties.
Reinforcement learning from human feedback
De meest gebruikte techniek is RLHF (Reinforcement Learning from Human Feedback). Hierbij leren we het model om outputs te genereren die mensen prefereren. Maar dit introduceert nieuwe theoretische uitdagingen. Hoe zorg je ervoor dat het model niet leert om het beloningssysteem te hacken? En hoe voorkom je dat het model zijn algemene capaciteiten verliest?
Het alignment trilemma
Onderzoekers hebben aangetoond dat er een fundamenteel trilemma bestaat in alignment. Je kan niet tegelijk sterke optimalisatie, hoge betrouwbaarheid en robuuste generalisatie hebben. Dit betekent dat perfecte alignment theoretisch onmogelijk is. Er zullen altijd trade-offs zijn.
Fase 5: inference
Eens het model getraind en aligned is, komt het moment van waarheid: het gebruiken in de praktijk. Deze fase brengt zijn eigen theoretische uitdagingen met zich mee.
In-context learning: leren zonder te leren
Een van de meest verrassende eigenschappen van LLM’s is in-context learning. Je geeft het model een paar voorbeelden in de prompt, en plots kan het een nieuwe taak uitvoeren zonder dat zijn parameters aangepast worden. Hoe is dit mogelijk?
De theorie suggereert dat het model tijdens training impliciete algoritmes leert die het tijdens inference kan uitvoeren. Het is alsof het model een meta-leerder wordt die kan aanpassen aan nieuwe situaties door de context te analyseren.
Chain-of-thought reasoning
Een andere fascinerende ontwikkeling is chain-of-thought reasoning. Door het model stap voor stap te laten redeneren, kunnen we de effectieve diepte van het netwerk vergroten. Dit laat het model complexere problemen oplossen. Maar er zijn grenzen: te veel redeneren kan leiden tot “overthinking” waarbij het model fouten accumuleert.
Fase 6: evaluatie
De laatste fase is misschien wel de moeilijkste: hoe evalueer je of een LLM goed werkt? Dit is niet zo simpel als het lijkt.
Benchmarks en hun beperkingen
Traditioneel gebruiken we benchmarks om modellen te evalueren. Maar deze hebben ernstige beperkingen. Modellen kunnen “shortcut learning” toepassen waarbij ze oppervlakkige patronen in de testdata exploiteren in plaats van echte begrip te tonen. Bovendien raken veel benchmarks verzadigd, waardoor ze niet meer kunnen onderscheiden tussen topmodellen.
Veiligheid en betrouwbaarheid
Een cruciaal aspect van evaluatie is veiligheid. Kunnen we garanderen dat een model geen schadelijke output genereert? Theoretisch onderzoek toont aan dat hallucinaties (het genereren van incorrecte informatie) wiskundig onvermijdelijk zijn voor elk berekenbaar model. Dit betekent dat we moeten leren leven met onzekerheid en robuuste detectiemechanismen moeten ontwikkelen.
De toekomst van LLM’s
Nu we de verschillende fases begrijpen, kunnen we kijken naar toekomstige evoluties. Waar gaat de ontwikkeling van LLM’s naartoe?
Multimodale modellen
De toekomst ligt in multimodale modellen die niet alleen tekst, maar ook beelden, audio en video kunnen verwerken. Dit vereist nieuwe theoretische frameworks om verschillende modaliteiten te integreren. De uitdaging is om een universele representatie te vinden die werkt over verschillende datatypes heen.
Efficiëntie en edge deployment
Een grote uitdaging is het efficiënter maken van LLM’s zodat ze op kleinere apparaten kunnen draaien. Technieken zoals quantisatie, pruning en knowledge distillation maken modellen kleiner zonder te veel prestaties te verliezen. De theoretische vraag is: wat is de minimale grootte die nodig is voor een bepaalde taak?
Multi-agent systemen
Een opwindende ontwikkeling is het gebruik van meerdere LLM’s die samenwerken. Deze agents kunnen complexe taken verdelen en samen tot betere oplossingen komen. Maar dit introduceert nieuwe uitdagingen rond coördinatie, communicatie en potentiële conflicten tussen agents.
Test-time compute scaling
In plaats van alleen grotere modellen te trainen, kunnen we ook meer rekenkracht gebruiken tijdens inference. Door het model langer te laten “nadenken” kunnen we betere resultaten krijgen. Dit opent nieuwe mogelijkheden maar vereist ook nieuwe theoretische inzichten in hoe we deze extra compute optimaal kunnen inzetten.
Conclusie: een voortdurende evolutie
De theoretische werking van LLM’s is een fascinerend en complex onderwerp dat zich over meerdere fases uitstrekt. Van data voorbereiding tot evaluatie, elke fase brengt zijn eigen uitdagingen en theoretische vraagstukken met zich mee. Wat duidelijk wordt, is dat we nog lang niet alles begrijpen over hoe deze modellen werken.
De toekomst belooft nog meer spannende ontwikkelingen. Multimodale modellen, efficiëntere architecturen en multi-agent systemen zullen de mogelijkheden van AI verder uitbreiden. Maar tegelijk blijven fundamentele vragen bestaan over veiligheid, betrouwbaarheid en de grenzen van wat mogelijk is.
Voor onderzoekers en ontwikkelaars betekent dit dat er nog veel werk aan de winkel is. We moeten de kloof tussen empirische successen en theoretisch begrip blijven dichten. Alleen zo kunnen we LLM’s bouwen die niet alleen krachtig zijn, maar ook betrouwbaar, veilig en transparant.
De reis van een LLM van lege architectuur naar intelligent systeem is een meesterwerk van moderne technologie en wetenschap. En het mooie is: we staan nog maar aan het begin van wat mogelijk is.